学院概况
About-
-
新闻公告
News -
师资队伍
Faculty -
科学研究
Research -
教学工作
Teaching -
学生事务
Student -
学院招生
Admission -
招聘信息
Careers
学院概况
About新闻公告
News师资队伍
Faculty科学研究
Research教学工作
Teaching学生事务
Student学院招生
Admission招聘信息
Careers在医学超声AI的科研活动中,持续、系统地追踪目标领域的前沿文献信息具有重要的战略意义。然而,在现实科研环境中,要真正做到持续、系统追踪目标领域的前沿文献信息,往往会面临多种困难:
1.对文献的获取、筛选、整理和分析存在困难:
文献获取渠道存在现实限制。高影响力期刊存在订阅和访问有限等因素,导致筛选过程中高质量期刊覆盖不全;在海量文献中进行信息筛选,当筛选方法缺乏体系化与科学性时,筛选工作效果不佳;文献信息的整理和分析要求高,需要兼顾便捷、美观、准确和实用,帮助研究者快速了解文献的学术价值以及适用性。
2.当前公开工具提供的解决方案存在明显不足:
传统人工追踪方式效率低下;智能 Agent存在数据库更新不及时、数据来源仍需要校验等问题;邮箱等推送方式未能对文献信息进行有效的整理和分析。
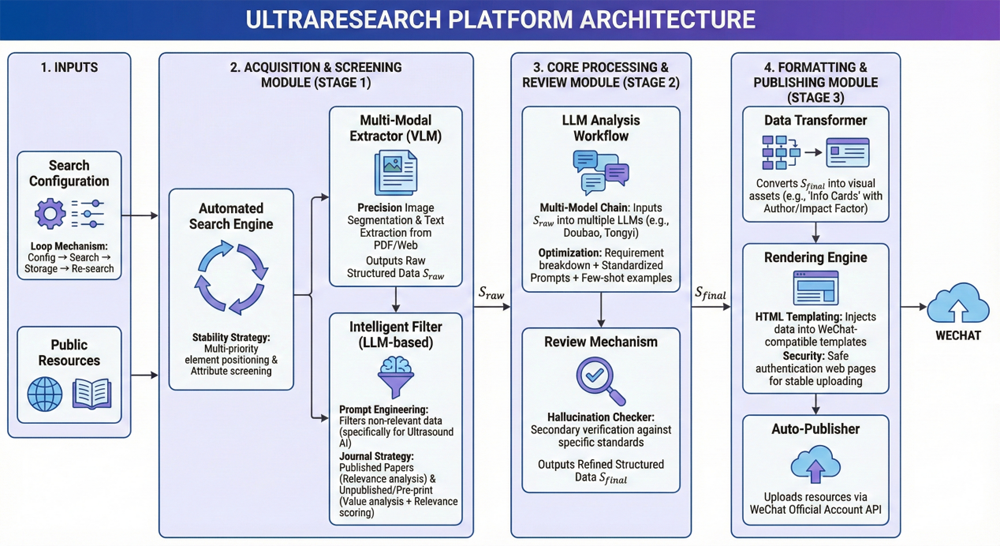
基于此,深圳大学医学部生物医学工程学院未来回声AI实验室的本科生团队在导师杨鑫副教授的指导下提出一个创新平台UltraResearch,该平台结合当前热门的大语言模型、智能体Agent和深度学习视觉模型等先进技术工具,智能化构建一套自动化工作流来管理文献获取、筛选、整理和分析的科研信息推送平台,辅助医学超声AI研究的科研用户高效、持续、系统地追踪目标领域的前沿文献信息。
UltraResearch平台介绍
一、UltraResearch基于公开资源库获取、筛选文献,并处理筛选后的文献输出结构化数据。
首先,基于公开的数据库,通过从“搜索条件配置-选择结构化储存-重新搜索”的循环实现文献的高质量获取。基于网站元素定位易受页面结构变化影响的问题,设计多优先级定位策略,通过多种特征自搜索匹配及元素属性筛查的组合方式,确保文献获取的正确性。
而后,对获取到的文献进行筛选。基于搜索返回结果与超声AI可能不相关的问题,UltraResearch引入了多个大语言模型(LLM),设计提示词工程筛选与超声AI强相关的文献,以提高筛选的准确性。具体实施方法如下:由于不同期刊文献类型有所差异,UltraResearch针对性部署不同的LLM模型,并设计优化提示词工程进行精确筛选。对于已正式发表的文献,LLM模型将分析文献与超声AI的相关性。对于In press或arXiv文献,LLM模型则对其进行价值分析与相关性分析。对文献的相关性评分进行排序最终输出筛选结果。
针对LLM模型对文献内容的处理效率与稳定性低的问题,UltraResearch部署了多模态视觉语言模型(Vision-Language Model, VLM)对筛选后的文献进行精准的图片分割与文字提取,并实现文献关键信息提取,并进而设计不同数据结构储存模型处理后的信息,最终输出文献的结构化数据。
二、UltraResearch部署多模态审查模型对文献的结构化数据进行科学逻辑校正。
UltraResearch建立了自动化的LLM工作流,将文献结构化数据依次输入多个LLM大语言模型(豆包、通义千问、DeepSeek等)进行提取和分析,通过拆解需求、设计标准化提示词结构、添加预期示例、调节模型核心参数并记录便于人工校正的模型深度推理思考记录,结合多轮测试迭代优化,提升LLM模型输出的精准度与一致性。
而后,UltraResearch设计了专门的数据结构对LLM模型的输出结果进行存储。针对LLM模型容易存在幻觉的问题,进一步地引入了科学逻辑审查模型并设计审查标准,对特定文献信息进行了二次审查和校正。
三、UltraResearch通过自动化排版流程及发布流程,对文献结构化数据的校正结果进行处理并形成推文上传到微信公众号平台。
以文献的信息卡为例,对文献的关键作者、影响因子、期刊名、发表年份、链接二维码等信息进行整合处理转化为文献的信息卡。对LLM模型输出结果与形式转化后的数据进行整合传输到推文模块。通过微信公众号的自动发布接口API上传图片等资源,并基于微信公众号对html格式的要求设计模板,采用渲染技术实现模板替换形成推文,设计认证网页对推文进行特殊处理,最终通过自动化发布脚本上传推文到微信公众号平台,由UltraResearch团队人工快速审核后正式发布。
UltraResearch团队介绍

UltraResearch平台的创建来源于深圳大学医学部生物医学工程学院本科生团队数月的辛勤付出。他们协同并进探索技术前沿,快速理解专业科研领域,同时又负责各自的技术领域,承担了各种项目管理角色。
陈嘉亮:24级生物医学工程创新班
负责:项目管理,对文献信息的获取、处理、整合、对文献质量与内容进行评估筛选,为模型提供可靠的结构化数据。
遇到的困难:基于文献排版多样,传统方法难以识别提取的问题,部署多模态模型识别提取文献内容和表格;基于搜索返回结果相关性差的问题,部署大语言模型分析文献内容。
郑煜涛:24级生物医学工程创新班
负责:部署模型处理筛选后的结构化数据,并实现将模型输出结果处理成不同类型的数据传递到推文输出模块,设计审查模型审查输出结果。
遇到的困难:针对大模型无法直接返回图片的问题,设计提示词工程让模型筛选出关键插图并进行标记,将图片处理结果整合到结构化的数据中。针对单一模型进行复杂任务容易出现注意力分散、幻觉等问题,加入模型审核机制,使用不同模型进行审核并设计提示词工程审查高出错率的环节,提高输出结果的准确性。
郭晓芳:23级生物医学工程创新班
负责:设计模型输出结果与推文模块对接的数据结构,实现自动化排版及推文自动发布流程;负责推文设计及平台运营。
遇到的困难:针对调用微信公众号自动发布接口实现的自动发布存在的排版问题筛查困难,不支持多种样式,因网络因素上传失败频率高的问题,设计自动化脚本并结合自动发布接口实现自动上传,确保上传模块的稳定性,为后续复杂排版的自动化打下基础;针对现有技术无法实现复杂排版自动化的问题,基于微信公众号的富文本编辑器属性及对样式的严格限制,设计安全认证网页及排版模板,并基于模板设计数据结构实现结果的稳定输出。
何晴:24级生物医学工程创新班
负责:实现从搜索条件配置到选择结构化储存再重新搜索的循环。针对不同期刊页面结构差异问题,引入配置化参数体系,通过动态参数适配多样化需求。通过多种特征自搜索匹配及元素属性筛查的组合方式,确保稳定识别。
遇到的困难:网站元素定位易受页面结构变化影响,为此设计多优先级定位策略,通过多种选择器确保稳定识别。
团队总结:
在过去的数月里,怀着解决科研工作者文献追踪痛点的初衷,团队成功构建了一套智能化的自动化工作流来管理文献获取、筛选、整理和分析的科研信息推送系统,实现了从数据源到成果输出的全流程自动化。
在团队协作的过程中,我们同样遇到许多问题。例如,早期数据结构不统一,总需要对小组成员的数据进行手动调整,通过讨论统一了数据结构,方便数据在不同板块流通;成员对产品的理解预期不同,通过与老师开会沟通,明确产品的定位与形式。
平台的初步成型,标志着我们在“持续、系统化追踪科研前沿”这一目标上迈出了坚实的第一步。我们期待它能成为科研工作者案头一款实用、高效的工具。
致谢

UltraResearch 平台从构想到初步实现,离不开学院给予的宝贵支持。在此,我们向学院表示最诚挚的感谢!团队将不断提高平台的迁移能力,从超声领域逐步推广到其他研究领域。
合作
我们诚挚欢迎对平台感兴趣的学院师生与我们联系,共同探讨平台的设计理论。我们将持续发布推文与更新系统,不断优化内容与呈现方式,提升平台的通用性。同时,我们也提供平台迁移服务,欢迎联系平台负责人开展合作。
联系方式:欢迎关注UltraResearch 公众号






