一、背景介绍:
人脑产生的具有个体特质的脑电波被称为“脑纹”。在信息时代对身份识别有着重要需求的背景下,有别于传统的指纹,声纹,脸部识别等身份识别方式,脑纹识别技术在不可窃取、不可伪造、不易受损、必须活体检测等方面具有独特的优势,能为身份识别提供更安全的生物识别方法,被称为最安全的下一代密码。然而目前脑纹识别的发展仍处于探索阶段,存在数据样本量小、测试时段单一、记录范式单一等一系列局限性。同时,目前没有公开的脑纹识别竞赛,缺乏统一的测试基准和平台阻碍了该领域的发展。为此,我们推出一个超过100人的多范式跨时段的脑电数据集,对脑纹识别问题提出公开的竞赛目标。
二、数据集介绍
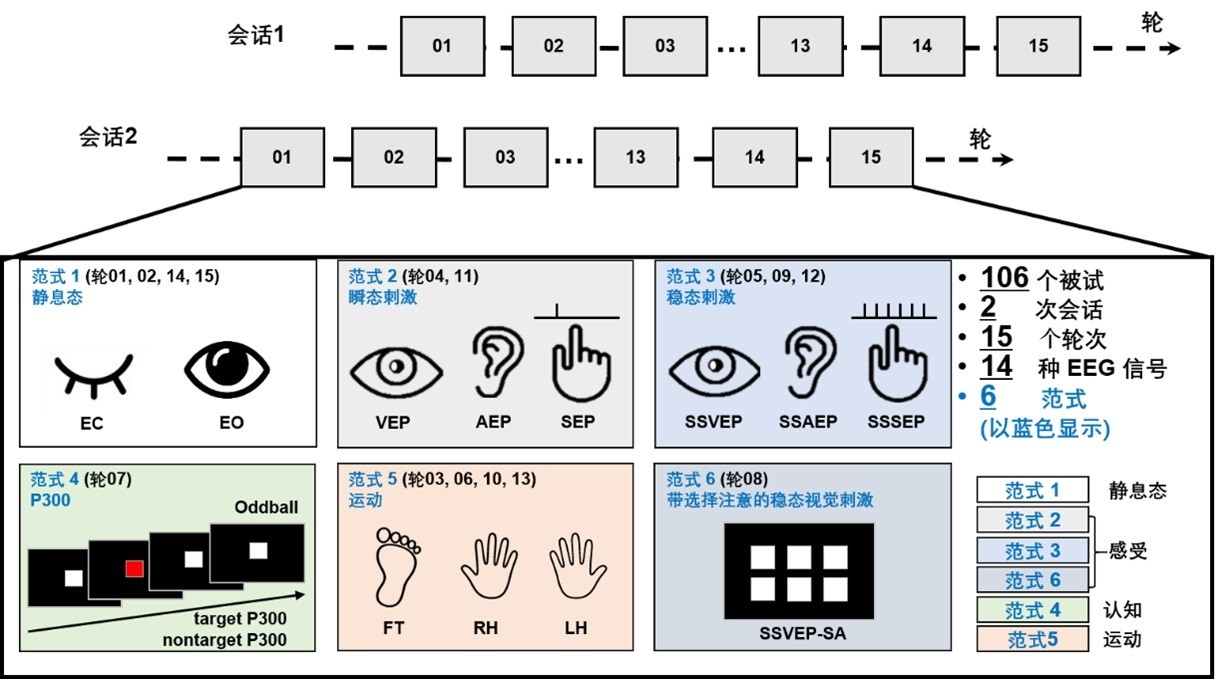
一个可靠的脑纹识别系统应能够抵御个体的精神状态变化(跨范式测试),并且能在数天返回后仍能成功识别个体(跨时段测试)。这里我们建立了一个包含106名被试、不同天的两次实验、多种范式的脑电数据库。其中95名被试参加了两次实验,间隔超过一周。实验包含静息态、任务态、脑机接口等6种脑电常见范式。据我们所知,以前的研究没有在超过100个被试的测试规模下评估脑纹识别算法在跨范式和跨时段场景下的测试性能。
三、竞赛规则
充分利用脑电个体间差异发展人工智能算法实现鲁棒有效的脑纹识别。鼓励参赛队伍利用多范式脑电数据进行跨时段的脑纹识别,提出针对个体内差异具有较好鲁棒性的脑纹识别算法。
(一) 数据集划分
该数据集包含106名被试,其中95名被试完成了两次实验。数据集分割方式如下:
1. 训练集(Calibration Set):20人
• 数据格式:提供两次实验的数据,且都含有被试编号。
• 用途:模型的预训练,可以下载,提供相应的函数支持
2. 注册集(Enrollment Set):95人
• 数据格式:提供每名被试一次实验的数据,且都含有被试编号。
• 训练集的20人的第一次试验数据也在注册集中
• 用途:用于脑纹识别模型的训练,不可下载
3. 测试集(Test Set)::A榜10人,B榜76人
• A榜: 10个人另一次实验的数据,其中2人不在注册集中。
• B榜: 76个人另一次实验的数据,其中9人不在注册集中。
• 用途:用于脑纹识别的测试,不可下载
所有数据集,我们均提供预处理完成后分割的数据
(二) 数据集划分竞赛任务
要求参赛者完成以下四个函数,提供相应的功能:
1. 训练mdl=Train(train_data, train_label):利用注册集中的数据train_data对应的标签train_label进行训练,得出训练模型mdl。
2. 匹配 y=Match(mdl, test_data, n): 判断测试集中的脑电信号是否是注册集的某一特定被试,程序输入训练好的模型mdl,测试数据test_data,判断的被试编号n,输出结果y提示是或者不是。身份匹配的主要应用场景是个人操作系统的登陆以及一些高级权限的授权。
3. 识别 y=Identification(mdl, test_data): 判断测试集中的脑电信号属于注册集的哪一个被试,程序输入训练好的模型mdl,测试数据test_data,输出结果y为被试编号。身份识别的主要应用场景是视频监控、信息检索等领域。
4. 验证 y=Verification(mdl,test_data):将测试集的脑电信号和注册集中的被试模板进行一一比对,程序输入训练好的模型mdl,测试数据test_data,输出结果y提示是不是该样本对应的被试是否在注册集中。程序输出结果为拒绝或接受。身份验证的主要应用场景是交易认证,访问控制系统,移动设备解锁等金融和信息安全领域。
四、竞赛方式
我们提供预处理的基本步骤和预处理后的数据,提供完成这项比赛最基本的代码和运行结果。搭建在线平台,供参赛队伍提交代码。需要指定Matlab和Python的运行环境。
• 比赛期间,参赛队伍每天可以提交一次代码,后台运算给出A榜的识别结果。A榜会有来自10名被试的200个测试样本。
• 比赛结束后,后台运算给出B榜的识别结果。B榜会有来自96名被试的2000个测试样本,安排不同的匹配(30%),识别(30%)和验证(30%)任务。
• A榜、B榜中的样本以匹配(40%),识别(40%)和验证(20%)的比例分配不同的任务。
• 最终竞赛结果以B榜匹配、识别和验证三种任务表现累加进行评价。
发起单位:深圳大学生物医学工程学院
联系人:黄淦
电子邮箱:huanggan@szu.edu.cn
